Il suono altro non è che la percezione, da parte dell'orecchio umano, di un'oscillazione delle molecole dell'aria. Il suono può quindi essere visto come un'onda, sia esso allo stato puro o memorizzato/trasmesso su un supporto elettromagnetico.
La tecnica più consueta per la
digitalizzazione del suono è la cosiddetta codifica PCM
(Pulse Code Modulation).
La digitalizzazione del suono in formato PCM avviene in due
passaggi:
Campionamento dell'onda: vengono prelevati dei valori (campioni) dell'onda, con una determinata frequenza detta frequenza di campionamento. Ad esempio, per lo standard CD audio, la frequenza di campionamento e' 44100 Hz (44100 campioni al secondo).
Quantizzazione dei campioni: il valore di ogni singolo campione viene approssimato (quantizzato) ad un valore intero. Tanto più è elevato il numero di valori interi tra cui scegliere, tanto più raffinata sarà l'approssimazione. Il numero dei valori possibili solitamente è dipendente dal numero di bit di quantizzazione: se chiamiamo Q questo numero, abbiamo 2Q possibili valori di quantizzazione. Nel caso del CD, si ha Q=16, da cui 216 = 65536 valori possibili.
Il segnale in formato PCM viene poi trasformato di nuovo in analogico compiendo i procedimenti inversi:
De-quantizzazione: ogni campione intero viene trasformato in un valore decimale compreso tra -1 e 1.
Viene ricostruita l'onda interpolando i valori così ottenuti.
Il processo di quantizzazione appena
descritto, per sua natura, rende differente
il segnale codificato e decodificato da quello
originale. La differenza fra i due segnali è detta rumore
di quantizzazione.
Se i bit di quantizzazione non sono sufficienti, il rumore di
quantizzazione può diventare udibile sotto forma di fruscìo;
il tipico esempio sono i file audio (WAV, AIFF, AU) codificati a
8 bit.
Più si aumentano i bit di quantizzazione, minore sarà la
differenza tra il segnale sorgente e decodificato e quindi meno
sarà udibile il rumore.
Nella normale codifica PCM, è necessario adottare 16 bit di quantizzazione per mantenere inudibile il rumore.
L'aumento dei bit di quantizzazione, allo
scopo di migliorare la qualità del suono decodificato,
corrisponde ad un aumento della mole di dati da gestire.
Per fare il solito esempio, lo standard CD audio (2
canali, parola di quantizzazione di 16 bit,
frequenza di campionamento di 44100 Hz) prevede
che la testina del lettore debba leggere un numero di bit al
secondo pari a
2 x 16 x 44100 = 1411 kbit/s.
Questo bitrate é troppo elevato, ad esempio, per
nastri magnetici non professionali
trasmissione del segnale audio via radio.
Si è quindi posto il problema di come diminuire il bitrate, per poter estendere lo standard di audio digitale "di qualità CD" a supporti meno sofisticati.
Si é studiato il modo per diminuire il bitrate riducendo il numero di bit di quantizzazione, cercando di mantenere comunque inudibile il rumore.
La riduzione del bitrate comporta un processo di codifica (compressione) del segnale PCM da parte del trasmittente, e di decodifica (decompressione) da parte del ricevitore.
Viene studiato e modellato il comportamento dell’apparato uditivo umano, per determinare l’udibilità del rumore di quantizzazione: possiamo diminuire il numero di bit di quantizzazione, fintanto che il rumore di quantizzazione si mantiene inudibile.
Nella psicoacustica, gioca un ruolo chiave il cosiddetto fenomeno di mascheramento: la presenza di una componente frequenziale influenza l’udibilità di altre componenti frequenziali. In altre parole, può succedere che una componente frequenziale mascheri (cioè renda inudibili) altre componenti frequenziali che sono simili alla prima.
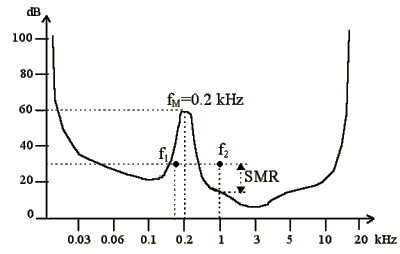
Viene definita quindi la funzione soglia di mascheramento M (funzione della frequenza), tale che M(f) é il valore minimo di intensità che la componente frequenziale f deve raggiungere per essere udibile (cioè, per non essere mascherata):
Nell'esempio del grafico, in presenza di fM (componente mascherante)
f1 non é udibile
f2 é udibile.
Definiamo quindi le quantitá
SNR (Signal to Noise Ratio - Rapporto Segnale-Rumore): differenza fra l’intensitá del segnale originale e quella del rumore di quantizzazione.
Segue che
piú é alto il valore SNR, piú é basso il rumore di quantizzazione rispetto al segnale, e quindi meno é udibile il rumore.
SMR (Signal to Mask Ratio - Rapporto Segnale-Maschera): differenza fra l’intensità della componente e quella della soglia di mascheramento globale; se una componente frequenziale é al di sotto della soglia di mascheramento M, allora non é udibile (SMR<0).
Confrontando le quantità SNR e SMR si può stabilire se il rumore di quantizzazione é udibile.
SNR - SMR = (S - N) - (S - M) = M - N.
Il rumore di quantizzazione é inudibile se N < M, ovvero se
SNR > SMR.
Segue che
possiamo permetterci di diminuire i bit di quantizzazione, fintanto che SNR > SMR.
Nel 1990, il Moving Pictures Expert Group (MPEG) ha definito uno schema di codifica di un segnale sonoro composto da un massimo di due canali codificati, con un bitrate uguale o inferiore a 384 kbit/s. Ciò corrisponde ad un fattore di compressione variabile da 4:1 a 12:1.
La codifica MPEG Audio adotta criteri psicoacustici per la riduzione dei bit di quantizzazione dei campioni. Il numero di bit di quantizzazione non è fisso per tutto il segnale come nella codifica PCM, ma varia dinamicamente a seconda del contenuto frequenziale del suono.
La codifica MPEG può avvenire secondo tre
diversi livelli di complessità ed efficienza, denominati layer
1-2-3. Il layer 3 è il più complesso ed efficiente
nella compressione, ed è conosciuto anche come formato MP3.
Il lavoro di tesi si è occupato della codifica MPEG-2
layer 2, per cui accennerò ora brevemente allo schema
di codifica MPEG layer 2.
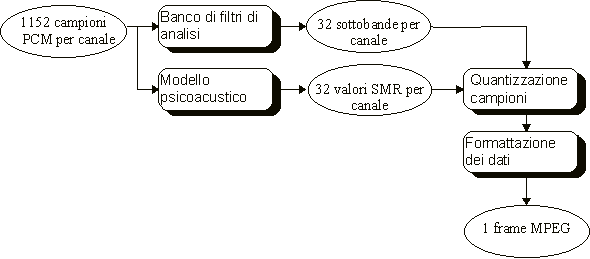
La procedura di codifica MPEG layer 2 può essere schematizzata nei passi seguenti:
Lettura di un blocco
di 1152 campioni PCM per ciascuno dei due canali Left e
Right.
Trasformazione, per
ciascun canale, del blocco di 1152 campioni (nel dominio
del tempo) in una sua rappresentazione nel dominio delle
frequenze tramite trasformata FFT (Fast Fourier
Transform) e, parallelamente, suddivisione in 32
sottobande dei campioni tramite un filtro di
analisi. Ogni sottobanda contiene 1152/32 = 36 campioni, nel dominio del
tempo
Calcolo dei 32 valori di
SMR (uno per sottobanda) tramite un modello
psicoacustico. Il modello psicoacustico si occupa di
calcolare un valore approssimativo (per eccesso) della soglia di
mascheramento, che
per comodità viene reso costante per tutti i campioni
della sottobanda. Dal valore della soglia di
mascheramento, e dall'intensità del segnale della
sottobanda, si ricava il valore SMR.
Quantizzazione e codifica
dei campioni di sottobanda. Per ciascuna sottobanda
di ciascun canale, viene deciso il numero di bit di
quantizzazione in base al valore SMR
ottenuto per quella sottobanda. Viene cioè scelto un
numero di bit di quantizzazione uguale o superiore al
valore minimo per cui SNR>SMR.
Per ogni sottobanda, tutti i suoi 36 campioni vengono
quantizzati con lo stesso numero di livelli.
Formattazione dei dati codificati e compressi in un blocco (frame) contenente entrambi i canali, con eventuale aggiunta di codice di protezione dagli errori (CRC - Cyclic Redundance Code) e aggiunta di informazioni ausiliarie (ad es.: canali aggiuntivi, e ogni genere di informazione "non udibile" associata al suono codificato). A questo punto i dati sono pronti per essere trasmessi.
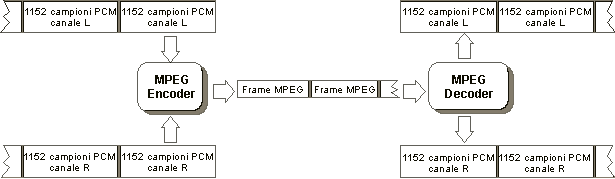
La dimensione del frame dipende dalla frequenza di campionamento e dal bitrate. Più é alto il bitrate, più il frame é ampio; una maggior dimensione del frame comporta quindi più spazio per allocare i bit dei campioni, e di conseguenza una qualità audio migliore. Per questo motivo, la scelta del bitrate da usare si rivela di importanza cruciale per quanto riguarda la qualità. Questo fatto é ancora più evidente nel caso della trasmissione di 5 canali, nello standard MPEG-2 Audio.
In fase di ricezione, ogni frame viene decodificato, per ottenere di nuovo 1152 campioni PCM per ogni canale:
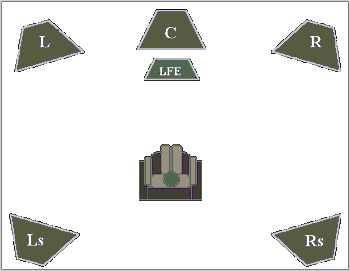
Nel novembre 1994, é stata ufficializzata l’estensione della codifica MPEG-Audio a quello che sarà lo standard sonoro dell’immediato futuro, il formato a 5+1 canali:
La sequenza prodotta da un codificatore MPEG-2 Audio BC é composta da
sequenza di frame MPEG compatibili
(eventuale) sequenza di frame estesi, parallela a quella MPEG:
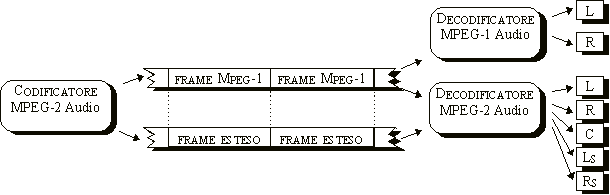
La sigla BC sta per Backward-Compatible (compatibile all'indietro). La sintassi della sequenza di frame MPEG-2 é tale, cioè, da renderne possibile la lettura da parte di un decodificatore MPEG, che si limiterà a leggere i primi due canali (tutti contenuti nei frame MPEG-1 compatibili), tralasciando gli altri tre.
Nella codifica MPEG-2 Audio,
ciascuno dei 5 canali viene codificato secondo lo schema MPEG
mostrato in precedenza.
Nella parte MPEG-1 compatibile (primi 2 canali), è possibile
trasmettere la somma stereofonica dei 5 canali,
in modo da rendere possibile l'ascolto dell'informazione sonora
di tutti e 5 i canali anche da un decodificatore MPEG-1, mixati
sotto forma di segnale stereo (canali Lo, Ro).
Una tale sequenza codificata richiederà quindi un de-mixaggio
da parte del decodificatore MPEG-2 prima di poter essere
ascoltata.
Questo processo è molto critico, in quanto il processo di
mixaggio-demixaggio digitale introduce una ulteriore quantità di
rumore nei canali de-mixati.
Nello standard MPEG-2, per i 3 canali ausiliari vengono aggiunte tre nuove tecniche di codifica, atte a ridurre ulteriormente lo spazio richiesto dai dati audio:
Codifica fantasma del canale centrale: le frequenze più alte del canale C non vengono codificate, ma vengono sommate ad entrambi i canali L ed R (sorgente monofonica "fantasma")
Dynamic crosstalk: in certi casi, sono solo le frequenze più basse a contribuire alla localizzazione spaziale della sorgente sonora nell’ambiente. Le frequenze più alte dei canali ausiliari, possono venire trasmesse su un canale solo, per essere poi copiate sugli altri canali in fase di decodifica
Predizione inter-canale: i canali ausiliari possono venire predetti da quelli MPEG-1 compatibili (Lo, Ro); i campioni dei canali ausiliari, cioè, possono essere calcolati in base ai campioni di Lo, Ro, facendone una combinazione lineare. Al posto di ogni sottobanda predetta, vengono trasmessi
i coefficienti per il ricalcolo dei campioni
i campioni dell’errore che si commette predicendo la sottobanda, codificati mediante il metodo consueto.
In fase di decodifica i campioni vengono ricalcolati mediante i coefficienti, e ad essi vengono quindi sommati i campioni dell’errore. Si presume che, per codificare il segnale di errore, occorrano meno bit di quantizzazione. La predizione inter-canale, per ogni sottobanda, viene adottata se induce ad un risparmio di bit, considerando il fatto che vanno trasmessi anche i coefficienti di predizione.
Durante la fase di sviluppo del software di codifica-decodifica MPEG-2 Audio, si é analizzata la possibilità di modificare lo standard, aggiungendo una quarta tecnica di codifica: la predizione intra-canale. Mediante questa tecnica, i campioni di sottobanda di ogni canale ausiliario possono venire predetti dai campioni precedenti dello stesso canale.
Il lavoro della tesi é consistito nello sviluppo di un’applicazione software in ambiente Linux, che realizza lo schema di codifica e decodifica secondo lo standard MPEG-2 Audio BC, per conto del Centro Ricerche RAI di Torino. Il relatore della tesi e coordinatore del progetto è stato Giorgio Dimino.
Il lavoro é parte di un progetto comune, nel quale sono coinvolti altri enti europei che lavorano allo sviluppo dello standard:
IRT (Institut für RundfunkTechnik - Germania)
Telekom (Germania)
Philips Research Laboratories (Olanda)
CCETT (Centre Commun d’Études de Télédiffusion et Télécommunications - Francia)
Alcatel-Telettra (Italia).
Si é trattato di un lavoro di
Valutazione dello schema proposto da MPEG: sviluppo dell’applicazione di codifica-decodifica
Proposta di miglioramento dello standard: aggiunta della predizione intra-canale allo standard e studio dei risultati ottenuti.
L’applicazione oggetto della tesi é stata l’unica, fra tutte quelle sviluppate dagli enti europei che lavorano sullo standard MPEG-2 Audio, in cui viene implementata la predizione intra-canale.
I risultati delle prove effettuate confermano che la predizione intra-canale, nella maggior parte dei casi, si rivela migliore della predizione inter-canale proposta in origine da MPEG-2, in termini di qualità audio in fase di ascolto.
Codifica e decodifica di un segnale a 5
canali, ad un bitrate di 512 kbit/s, che rappresenta tre note
consecutive emesse da un’accordatore di chitarra (simile,
come timbro, all’armonica a bocca).
La codifica é stata fatta
con la predizione intra-canale
senza la predizione intra-canale.
É stato quindi analizzato l’andamento
nel tempo del valore SNR in entrambi i casi.
Il grafico seguente mostra il risultato dell'analisi. Sull'asse
orizzontale è espresso il tempo misurato in numero di frame
MPEG.
Per brevità, riporto solo il grafico relativo ai valori SNR
misurati per il canale L (left). L'andamento per
gli altri canali si è rivelato analogo.
Ricordo che maggiore è il valore SNR, meno è udibile il rumore
di quantizzazione.
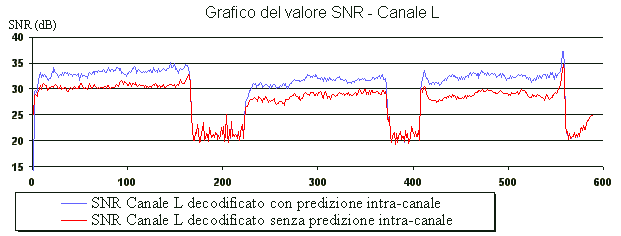
Dal grafico si può vedere come la predizione intra-canale abbia contribuito ad aumentare di circa 3 dB il valore medio del valore SNR, che corrisponde ad un abbassamento di 3 dB del rumore di quantizzazione.
La predizione inter-canale, proposta da MPEG, non si é rivelata altrettanto efficace: il miglioramento della qualitá prodotto dalla predizione inter-canale é all’incirca 1/3 di quello prodotto dalla predizione intra-canale, a parità di segnale audio sorgente.
Copyright (C) 1996 Luciano Morpurgo